
📗 데이터베이스란?
DB
: 데이터를 효율적으로 보관하고 꺼내볼 수 있는 곳
⇨ 장점 : 많은 사람이 안전하게 데이터를 사용하고 관리 가능
(동시 접근할 수 있어야 함)
📍 DBMS
- DB를 관리하기 위한 SW
- 분류 : 관계형, 객체-관계형, 도큐먼트형, 비관계형 등 (관리 특징에 따라)
- 예) 관계형 ; ORACLE, MySQL
▷ RDBMS (관계형 DBMS)
- 테이블 형태로 이뤄진 데이터 저장소
- 관계형 모델 기반
▷ H2, MySQL
- H2 : 스프링 부트가 지원하는 인메모리 관계형 DB. (JAVA로 작성, 테스트용)
- MySQL : 실제 서비스 올리는 용
➕ DB 기초 용어
- 테이블 : DB에서 데이터 구성하기 위한 가장 기본적 단위
- 행 : 테이블의 가로로 배열된 데이터 집합 (=레코드) & 기본키 가짐
- 열 : 행에 저장되는 유형의 데이터 (=속성) & 무결성 보장
- 기본키 : 행을 구분할 수 있는 식별자. & 유일성,최소성, 불변성 만족. & 중복 X & NOT NULL
- 쿼리 : DB에서 CRUD 처리를 하기 위해 사용하는 명령문 (SQL 사용)
📗 ORM이란?
자바의 객체와 DB를 연결해 JAVA로만 DB를 다룰 수 있게 하는 프로그래밍 기법 (Object-Relational Mapping)
- 👍 장점
1) SQL을 직접 작성하지 않고, 사용하는 언어로 DB에 접근 가능
2) 객체지향적 코드 작성 가능 - 비즈니스 로직에만 집중 가능
3) DB 시스템에 대한 종속성 줄어듦
4) 매핑하는 정보가 명확하므로 ERD에 대한 의존도 낮출 수 있음 & 유지보수에 유리
- 👎 단점
1) 프로젝트가 복잡할수록 사용 난이도도 올라감
2) 복잡하고 무거운 쿼리는 ORM만으로 해결 불가
- 종류 : JPA
📗 JPA와 하이버네이트
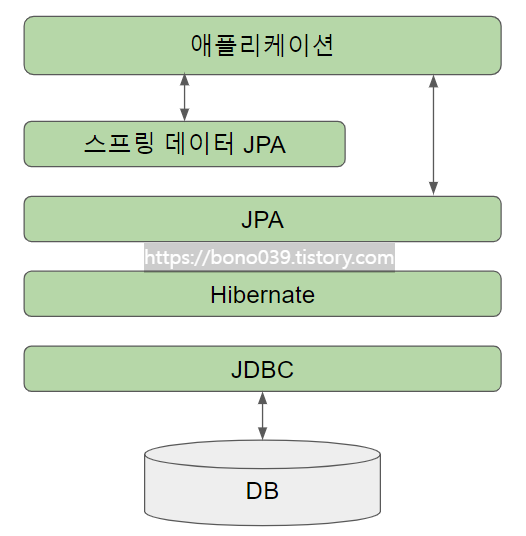
📍 JPA (Java Persistence API)
JAVA에서 관계형 DB를 사용하는 방식을 정의한 인터페이스
- 실제 사용 위해선 ORM 프레임워크를 추가로 선택해야 함 ⇨ Hibernate
- 자바 객체와 DB연결해 데이터 관리
📍 Hibernate
JPA 인터페이스를 구현한 구현체이자 JAVA용 ORM 프레임워크
- JDBC API 사용
- 목표 : 자바 객체 통해 DB 종류에 상관없이 DB를 자유롭게 사용할 수 있게 하는 것
📗 엔티티 매니저란?
📍 엔티티
- DB 테이블과 매핑되는 객체 (= 영속성 가진 객체)
- DB의 테이블과 직접 연결된다는 특징 때문에 일반 객체와 구분지어 부름
- DB에 영향을 미치는 쿼리를 실행하는 객체
📍 엔티티 매니저
- 엔티티를 관리해 DB와 애플리케이션 사이에서 객체 생성,수정,삭제 등의 역할을 하는 것
- "엔티티 매니저 팩토리" : 엔티티 매니저 만드는 곳
- @PersistenceContext / @Autowired 통해 엔티티 매니저 사용하므로 직접 생성.관리할 필요 X
- 특징 : 엔티티를 영속성 컨텍스트에 저장
➕ 영속성 컨텍스트란?
엔티티를 관리하는 가상의 공간
- JPA의 중요한 특징 중 하나
- 특징 : 1차 캐시, 쓰기 지연, 변경 감지, 지연 로딩
- 👍 : DB 접근을 최소화해 성능을 높임 .ᐟ
① 1차 캐시
- 캐시 키 : 엔티티의 @Id 애너테이션이 달린 기본키 역할을 하는 식별자이며, 값은 엔티티
- 엔티티 조회 시, 1차 캐시에서 데이터를 조회하고 값이 [있으면 반환 / 없으면 DB에서 조회해 1차 캐시에 저장한 후 반환]
- 👍 : 캐시된 데이터 조회 시, DB를 거치지 않아도 되므로 빠르게 데이터 조회 가능
② 쓰기 지연
- Transactional Write-Behind
- 트랜잭션 커밋 전까지는 질의문을 보내지 않고 쿼리를 모아뒀다가, 트랜잭션을 커밋하면 모았던 쿼리를 한 번에 실행
- 👍 : 적당한 묶음으로 쿼리를 요청할 수 있어 시스템 부담 줄일 수 있음
③ 변경 감지
- 트랜잭션 커밋 시, 1차 캐시에 저장되어 있는 엔티티 값과 현재 엔티티 값을 비교해 변경된 값이 있다면
변경 사항을 감지해 변경된 값을 DB에 자동 반영
- 👍 : 적당한 묶음으로 쿼리를 요청할 수 있어 시스템 부담 줄일 수 있음 (= 쓰기 지연 장점)
④ 지연 로딩
- 쿼리로 요청한 데이터를 애플리케이션에 바로 로딩하는 것이 아니라, 필요할 때 쿼리를 날려 데이터 조회
- ↔ 즉시 로딩
📍 엔티티의 상태
① 비영속 상태 - 영속성 컨텍스트와 전혀 무관 ⇨ 엔티티 처음 만들면
② 관리 상태 - 영속성 컨텍스트가 관리 O ⇨ em.persist()
③ 분리 상태 - 영속성 컨텍스트가 관리 X ⇨ em.detach()
④ 삭제된 상태 ⇨ em.remove()
📗 스프링 데이터와 스프링 데이터 JPA
스프링 데이터
: 비즈니스 로직에 더 집중할 수 있게 DB 사용 기능을 클래스 레벨에서 추상화 한 것
⇨ 스프링 데이터에서 제공하는 인터페이스 통해 스프링 데이터 사용
⇨ CRUD 포함. 쿼리 알아서 만듦. 페이징 처리 기능
📍 스프링 데이터 JPA란?
스프링 데이터의 공통적 기능 + JPA의 유용한 기술
(= JPA를 쓰기 편하게 만들어 놓은 모듈)
- 리포지토리 역할을 하는 인터페이스를 만들어 DB의 CRUD 작업 수행
(기존 : 메서드 호출 통해 엔티티 상태 변경)
public interface MemberRepository extends JpaRepository<Member, Long> {
}
📍 스프링 데이터 JPA에서 제공하는 메소드 사용해보기
○ [springbootdeveloper - MemberService.java]
: JpaRepository에서 제공하는 메소드 사용해보기
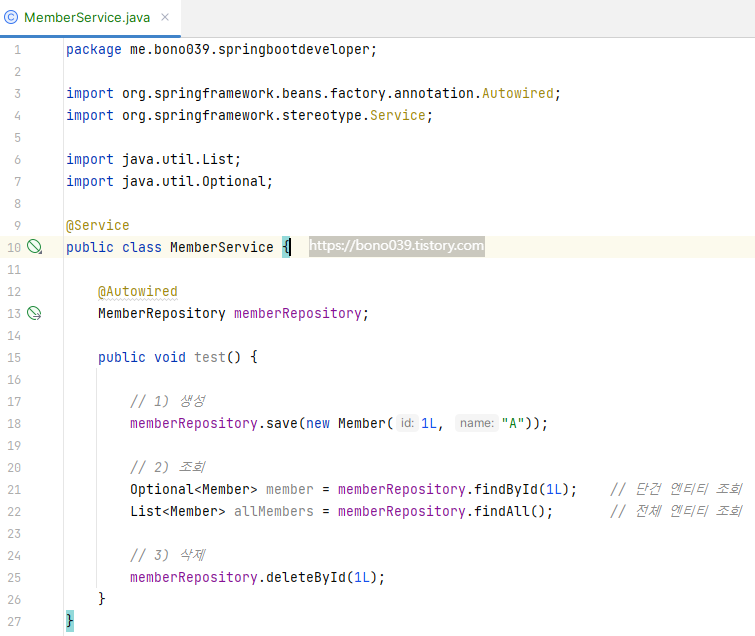
• save() : 조회 (CREATE)
• findById() : 단건 조회 (Read) / findAll() : 전체 조회 (Read)
• deleteById() : ID 지정해 엔티티 삭제
• delete() : 엔티티를 전달 인수로 넘겨 삭제
○ Member.java

@NoArgsConstructor
- 기본 생성자
- 접근 제어자 : public / protected
@ Entity
- 테이블과 매칭
@GeneratedValue
- 기본키 생성 방식 결정 (Line 15)
⇨ AUTO : 선택한 DB 방언에 따라 방식을 자동을 선택 (default)
⇨ IDENTITY : 기본키 생성을 DB에 위임 (= AUTO_INCREMENT)
⇨ SEQUENCE : DB 시퀀스를 사용해 기본키 할당 (ORACLE)
⇨ TABLE : 키 생성 테이블 사용
@ Column
- DB 컬럼과 필드 매핑
⇨ name : 필드와 매핑할 이름 (default : 필드명으로 지정)
⇨ nullable : 컬럼의 null 허용 여부 (default : true = nullable)
⇨ unique : 컬럼의 유일한 값 여부 (default : false = non-unique)
⇨ columnDefinition : 컬럼 정보 설정
○ MemberRepository.java
public interface MemberRepository extends JpaRepository<Member, Long> {
}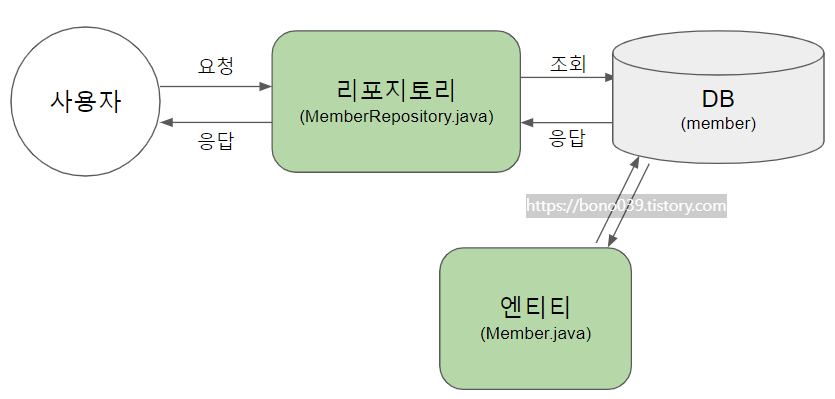
- 리포지토리 : 엔티티에 있는 데이터들 CRUD 할 때 사용하는 인터페이스.
⇨ 스프링 데이터 JPA에서 제공하는 인터페이스인 JpaRepository 클래스 상속받아 구현
(해당 글 내용은 📗 스프링 부트 3 백엔드 개발자 되기 - 자바 편을 읽고 정리한 내용입니다.)
'📚 관련 독서 > 스프링 부트 3 백엔드 개발자 되기 - 자바 편' 카테고리의 다른 글
| [SpringBoot] 07장 블로그 화면 구성하기 (타임리프) (0) | 2024.02.08 |
|---|---|
| [SpringBoot] 06장 블로그 기획하고 API 만들기 (0) | 2023.08.17 |
| [SpringBoot] 04장 스프링 부트 3와 테스트 (0) | 2023.08.11 |
| [SpringBoot] 03장 스프링 부트 3 구조 이해하기 (0) | 2023.08.11 |
| [SpringBoot] 2.4 스프링 부트 3 코드 이해하기 (0) | 2023.08.10 |